Here in our house we keep our plants on the threshold of death. They are in constant limbo as we remember to water them every few months. It is really quite disgraceful.
 Our sad sad plant.
Our sad sad plant.
One day I looked at our plants and thought we needed to do something. Go and water them? The plant doesn’t just need water. It is suffering from the systemic problem of us never remembering to water it. No. Watering the plant would be too easy, we need a technological solution that will hydrate the plant and not require us to change our comfortable habit of neglect.
I googled “automated house plant watering” and the first link that comes up is an instructable. It promised to be a cheap and easy project. So I went ahead and got all the materials: an aquarium air pump, some tubing and valves. I then followed the instructions and assembled the parts as they describe. The result was underwhelming. I got some gurgling at the plant end of the tube, not a steady or measurable flow. I really don’t understand the physics that makes that system work, but it has a lot to do with water pressure: the deeper your reservoir the more efficient the water gets pumped. As the water gets consumed, the pump gives less output. So to get an optimal plant-watering we would need to make sure the tank is always full. Whats the point of automating it if you have to fill the tank after every watering?? This won’t do. I plan to put this on a timer. I need to know that if I have it on for 1 minute I will always pump a comparable amount of water to the plant.
So I got to thinking, how can an air pump pump water? Specifically, how can it pump water with a constant pressure? I came up with this schematic:
 Air is pumped into a sealed jar with an outlet tube that relieves the jar’s pressure by pushing water out through another tube!
Air is pumped into a sealed jar with an outlet tube that relieves the jar’s pressure by pushing water out through another tube!
I grabbed a mason jar and drilled two 3/16″ holes in the lid. This allowed me to insert the two air tube which are slightly thicker (5mm). They fit snuggly and formed a seal.

Next I attached one of the tubes to the pump, and placed the second one’s end in a glass. Turned on the pump and! Yes! It works! Science! I was getting a steady flow of water. The jar was emptied in a constant rate. This setup will do. I’m so pleased with this!
I splurged and got a slightly more expensive pump with 4 outputs so I can water 4 plants individually.

This setup has a few advantages over other pump setups:
- It is cheap. So far the bill of parts is around $12.50.
- It offers predictable water throughput.
- You can connect any sealable container. Don’t want to refill the water after 32oz of watering? Get a gallon jug.
- If the reservoir runs dry the motor won’t catch fire. That apparently is a thing water pumps.
- Since the water is only going through a simple tube and not an expensive motor, you can pump a nutrient solution. If you want to pamper your plants, we don’t.
I made a stupid pump. Why is that cool? Because with a WiFi plug it becomes smart! It is now a Connected Device™. I plugged it into a Bayit WiFi socket, and set it to turn on for 20 seconds each Monday afternoon. That will feed our plants about a 1/2 a cup a week. If we like the results we may extend it to a full cup!
 The Internet is in control!
The Internet is in control!
A Word on WiFi Sockets
They suck. They take the simplest operation of closing a circuit and abstract it in a shitty smartphone app that only works half the time. Well, at least that has been my impression with this Bayit gadget. For my next project I am going to use a Kankun smart plug. Apparently it runs OpenWRT and is very hackable.
Bill of Materials
|
Air Pump
|
$6.99
|
|
Air tube
|
$3.42
|
|
Mason jar
|
$2.09
|
|
Wifi plug
|
$24.99
|
In my last post, I covered the speech rate problem as I perceived it. Understanding the theory of what is going on is half the work. I decided to make a cross-platform speech rate benchmark that would allow me to identify how well each platform conforms to rate changes.
So how do you measure speech rate? I guess you can count words per minute. But in reality, all we want is relative speech rate. The duration of each utterance at given rates should give us a good reference for the relative rate. Is it perfect? Probably not. Each speech engine may treat the time between words, and punctuation pauses differently at different rates, but it will give us a good picture.
For example. If it takes a speech service α seconds to speak an utterance, it should take it α/2 seconds to to say the same thing with a rate of 2.0, or 2α at a rate of 0.5. If we want to measure the engines rate compliance across a set of different rates, we first get the utterance time with a “normal” rate of 1.0, and then the rest is simple division.
I wrote a tool to do just this. Play around with it. It is fun.
Speech Rates in OSX
As I mentioned in the previous post, it looks like our OSX speech support is the only platform where we actually got it right. Running the rates benchmark on the Alex voice gives us these results:
|
Voice
|
1/2.5
|
1/2.25
|
1/2
|
1/1.75
|
1/1.5
|
1/1.25
|
1
|
1.25
|
1.5
|
1.75
|
2
|
2.25
|
2.5
|
|
Alex
|
0.415
|
0.459
|
0.521
|
0.593
|
0.688
|
0.826
|
1.00
|
1.27
|
1.52
|
1.75
|
1.99
|
2.23
|
2.48
|
You know what would be prettier than a table? A graph! So I made the benchmark generate a graph that gives a good visualization of the rate distribution. I normalized it with a log10 so that you can get a better idea of distances in the graph. Here is what it looks like for a rate-conforming voice like Alex:
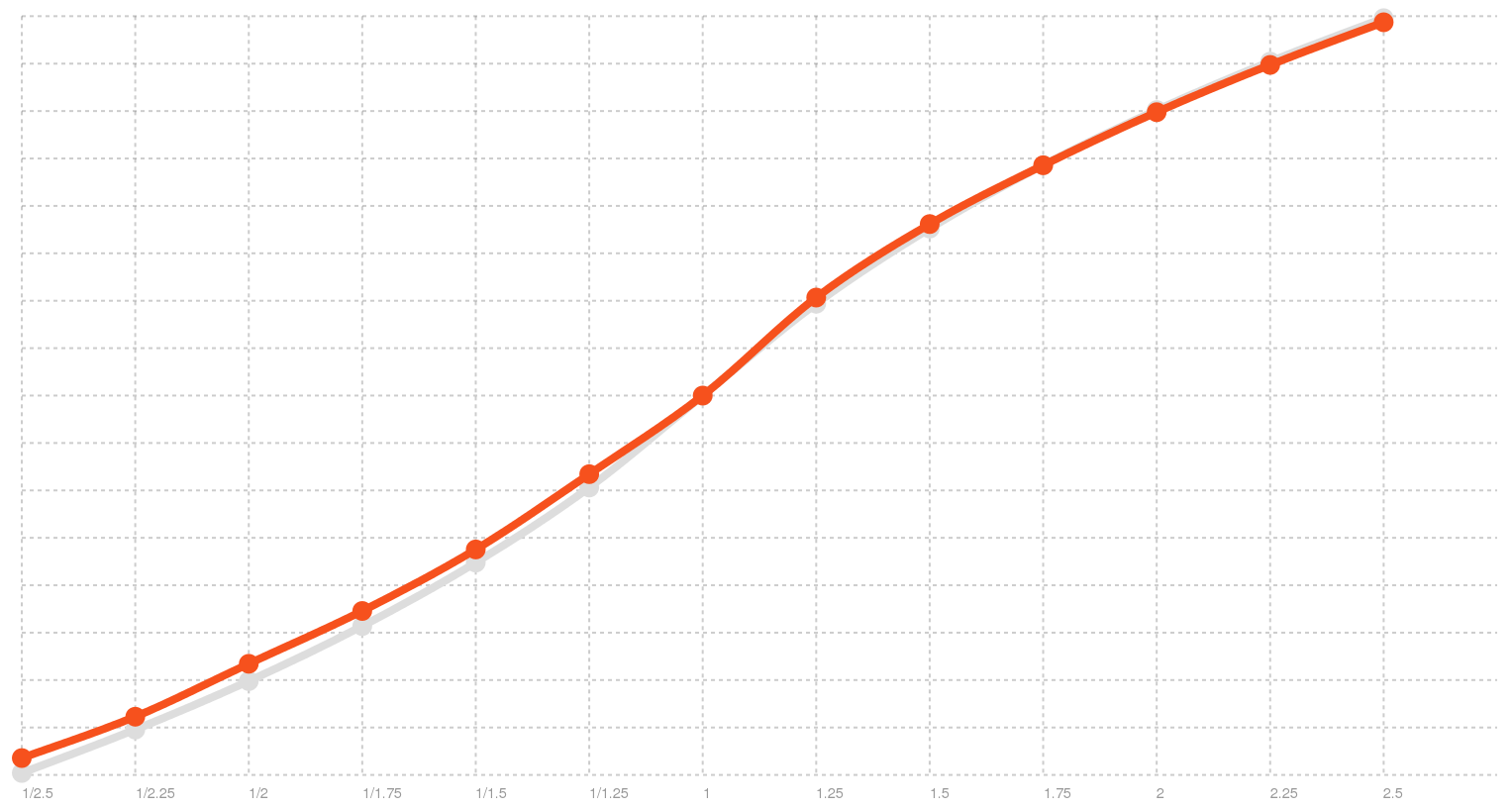 Rate distribution of Alex voice on OSX
Rate distribution of Alex voice on OSX
OSX voices aren’t perfect. For example, the Hebrew Carmit Voice does not support rates under 0.5 (or above 3, but that is not shown here). If a rate out of the supported range is given, the voice will just go back to its default. That’s not too good! There may be some workarounds to make sure we at least use the max/min rate, but I didn’t check it out yet.
|
Voice
|
1/2.5
|
1/2.25
|
1/2
|
1/1.75
|
1/1.5
|
1/1.25
|
1
|
1.25
|
1.5
|
1.75
|
2
|
2.25
|
2.5
|
|
Carmit
|
0.926
|
0.927
|
0.520
|
0.584
|
0.686
|
0.818
|
1.00
|
1.27
|
1.54
|
1.75
|
2.04
|
2.30
|
2.53
|
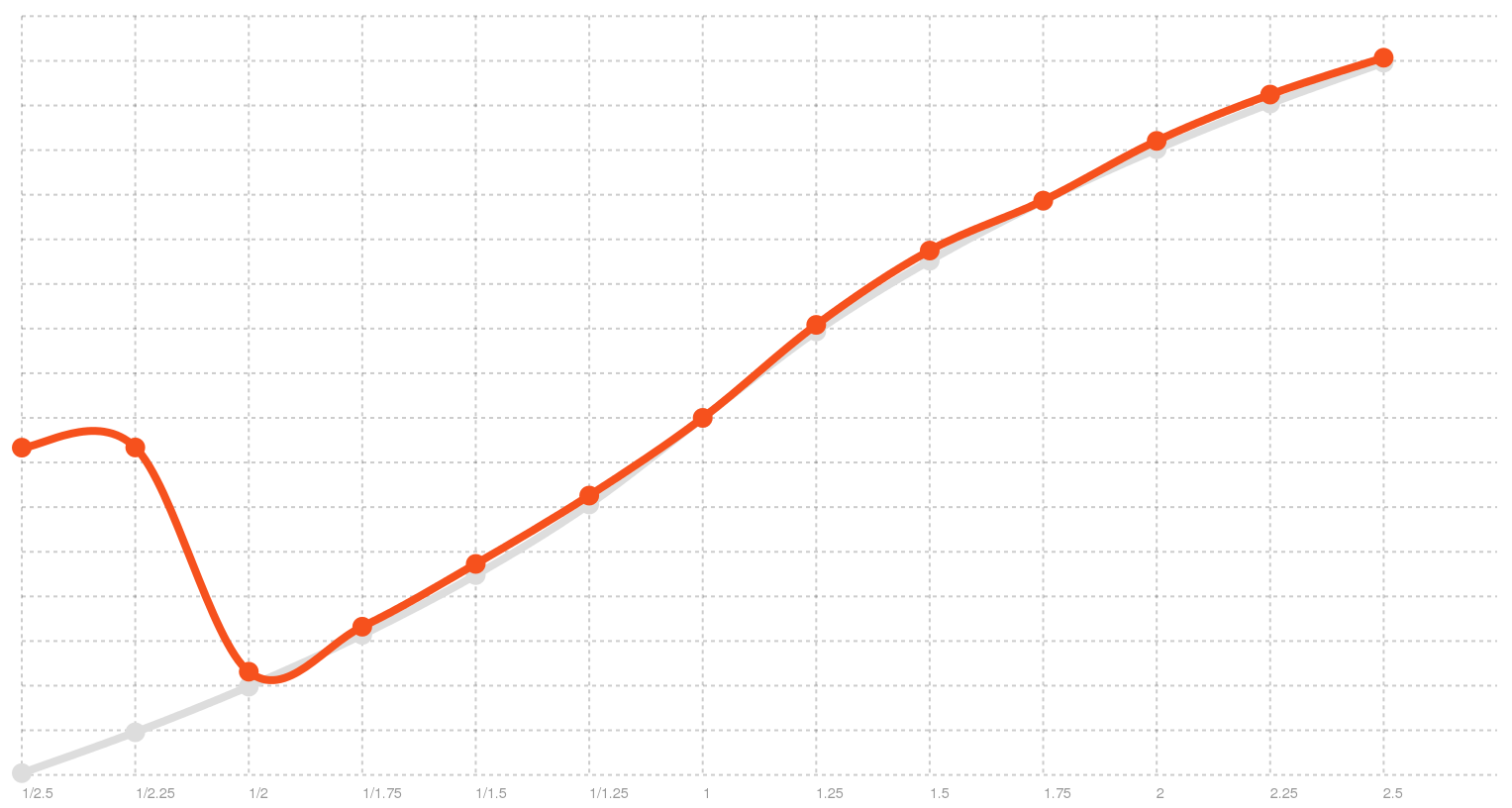 Carmit rate distribution
Carmit rate distribution
It could even be worse. OSX has a voice named “Bad News”. Apparently, there is only one rate in which to deliver bad news:
|
Voice
|
1/2.5
|
1/2.25
|
1/2
|
1/1.75
|
1/1.5
|
1/1.25
|
1
|
1.25
|
1.5
|
1.75
|
2
|
2.25
|
2.5
|
|
Bad News
|
0.882
|
0.899
|
0.917
|
0.937
|
0.956
|
0.978
|
1.00
|
1.02
|
1.03
|
1.04
|
1.05
|
1.05
|
1.06
|
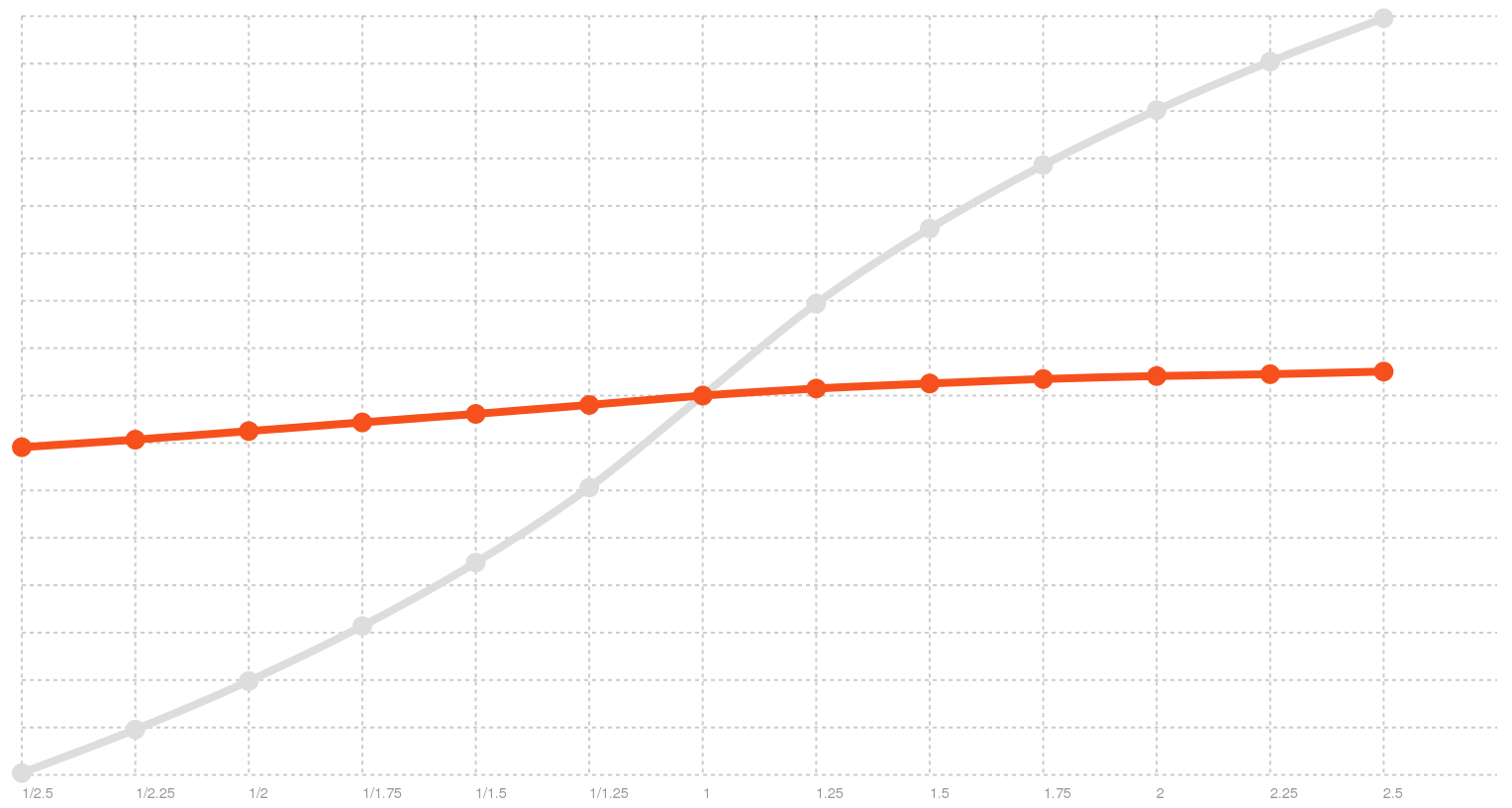 Bad News rate distribution
Bad News rate distribution
With a few exceptions, speech rate on OSX is pretty good. Their API and documentation is straightforward enough that we nailed this on the first shot.
Speech Rates in Windows
As mentioned in the previous post, speech rate in SAPI is defined as an integer from -10 to 10. In our initial implementation, we naively assumed that we can take the Web Speech API rate multiplier, and convert it to an SAPI rate by using the 10th root of the value and multiplying it by ten. In effect, projecting the maximal distribution of SAPI speech rates across the allowed Web Speech API values: 0.1 would become -10, 10 would be 10.
With my fancy new benchmark tool, we could get a good picture of where that leads us with the standard David voice:
|
Voice
|
1/2.5
|
1/2.25
|
1/2
|
1/1.75
|
1/1.5
|
1/1.25
|
1
|
1.25
|
1.5
|
1.75
|
2
|
2.25
|
2.5
|
|
MS David
|
0.712
|
0.713
|
0.712
|
0.799
|
0.892
|
0.976
|
1.00
|
0.977
|
1.13
|
1.25
|
1.41
|
1.40
|
1.40
|
That’s not too good. For example, if you provide a rate of 2.0, you would expect double the normal rate, but you only get 1.41x. Here is a graph:
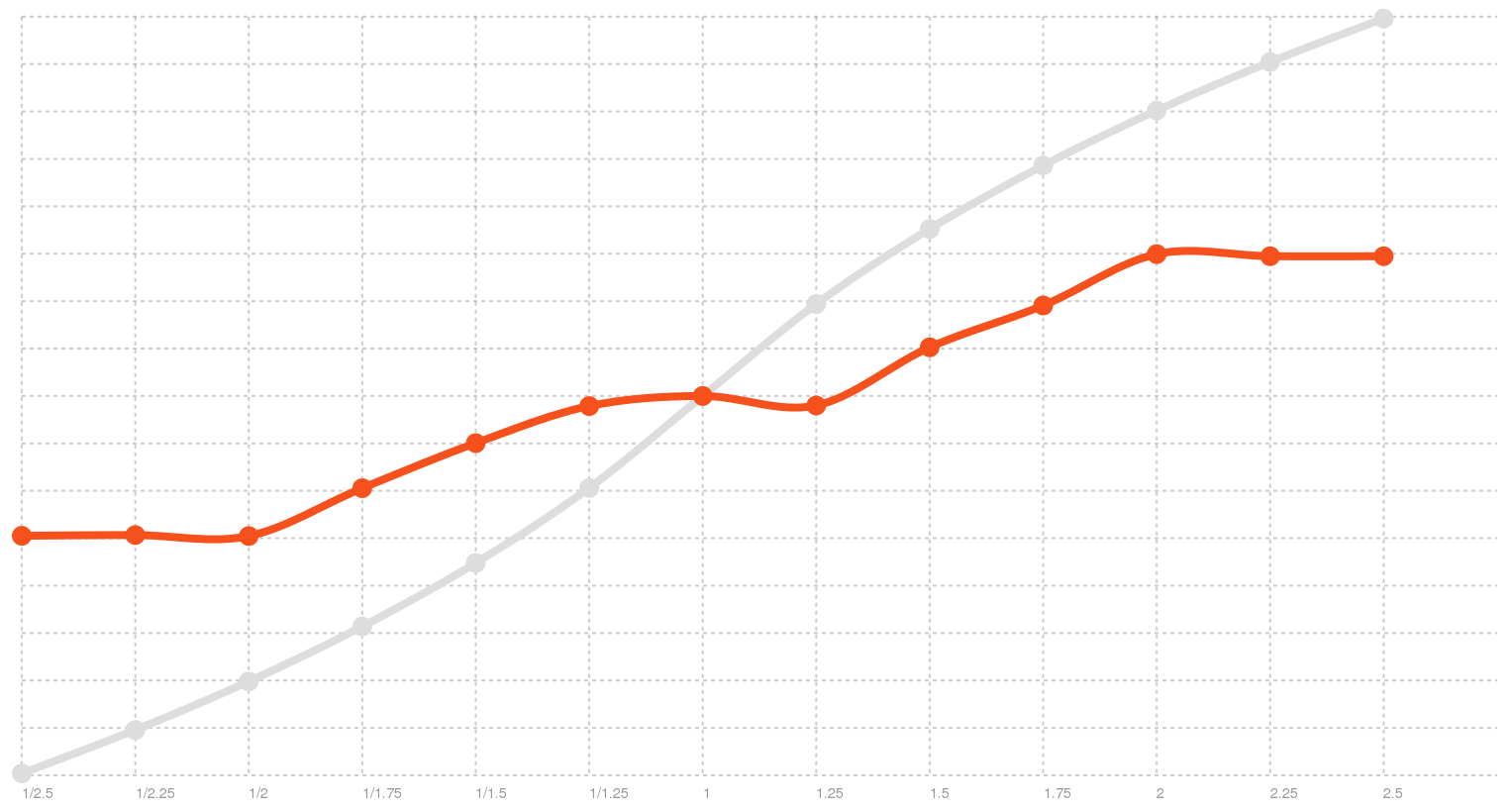 Broken rate distribution on Windows
Broken rate distribution on Windows
I also mentioned in the previous post, that after digging in MSDN, I found a page that explains what the expected speech engine characteristics are. In essence, 10 in SAPI means three times the normal speed, and -10 is one third. That is something to work with! I fixed the math we do for the rate conversion, and once we correctly projected our multiplier values into what SAPI accepts we got much better benchmark results:
|
Voice
|
1/2.5
|
1/2.25
|
1/2
|
1/1.75
|
1/1.5
|
1/1.25
|
1
|
1.25
|
1.5
|
1.75
|
2
|
2.25
|
2.5
|
|
MS David
|
0.413
|
0.454
|
0.509
|
0.568
|
0.713
|
0.799
|
1.00
|
1.25
|
1.40
|
1.76
|
1.97
|
2.19
|
2.41
|
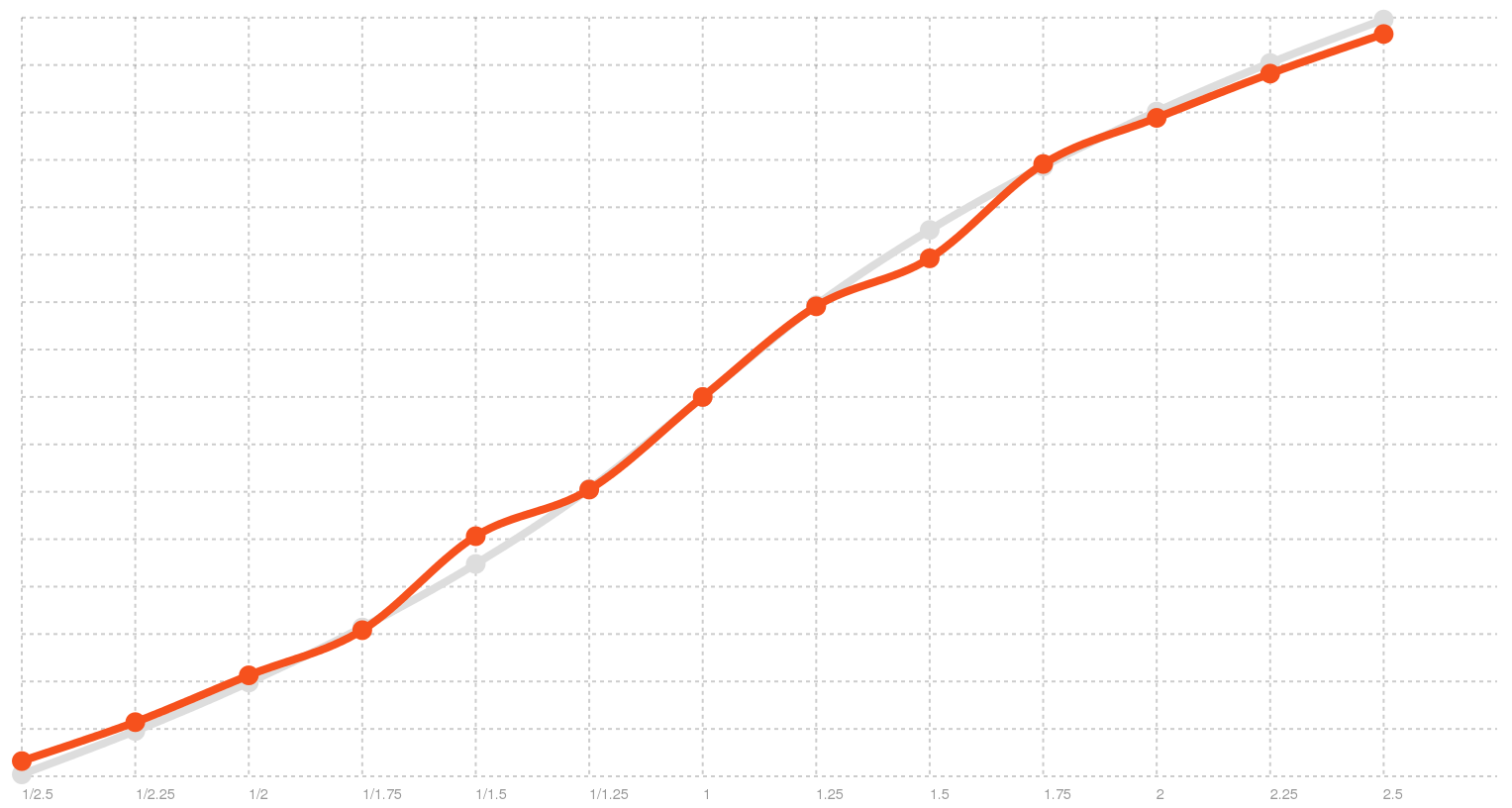 Fixed Windows rate distribution
Fixed Windows rate distribution
Speech Rates in Linux
In Linux, we originally had the same naive conversion that we had in Windows, with the only diff being that in Speech Dispatcher the rate is an integer from -100 to 100. The results were just as bad:
|
Voice
|
1/2.5
|
1/2.25
|
1/2
|
1/1.75
|
1/1.5
|
1/1.25
|
1
|
1.25
|
1.5
|
1.75
|
2
|
2.25
|
2.5
|
|
default
|
0.659
|
0.684
|
0.712
|
0.757
|
0.804
|
0.887
|
1.00
|
1.01
|
1.07
|
1.07
|
1.14
|
1.15
|
1.20
|
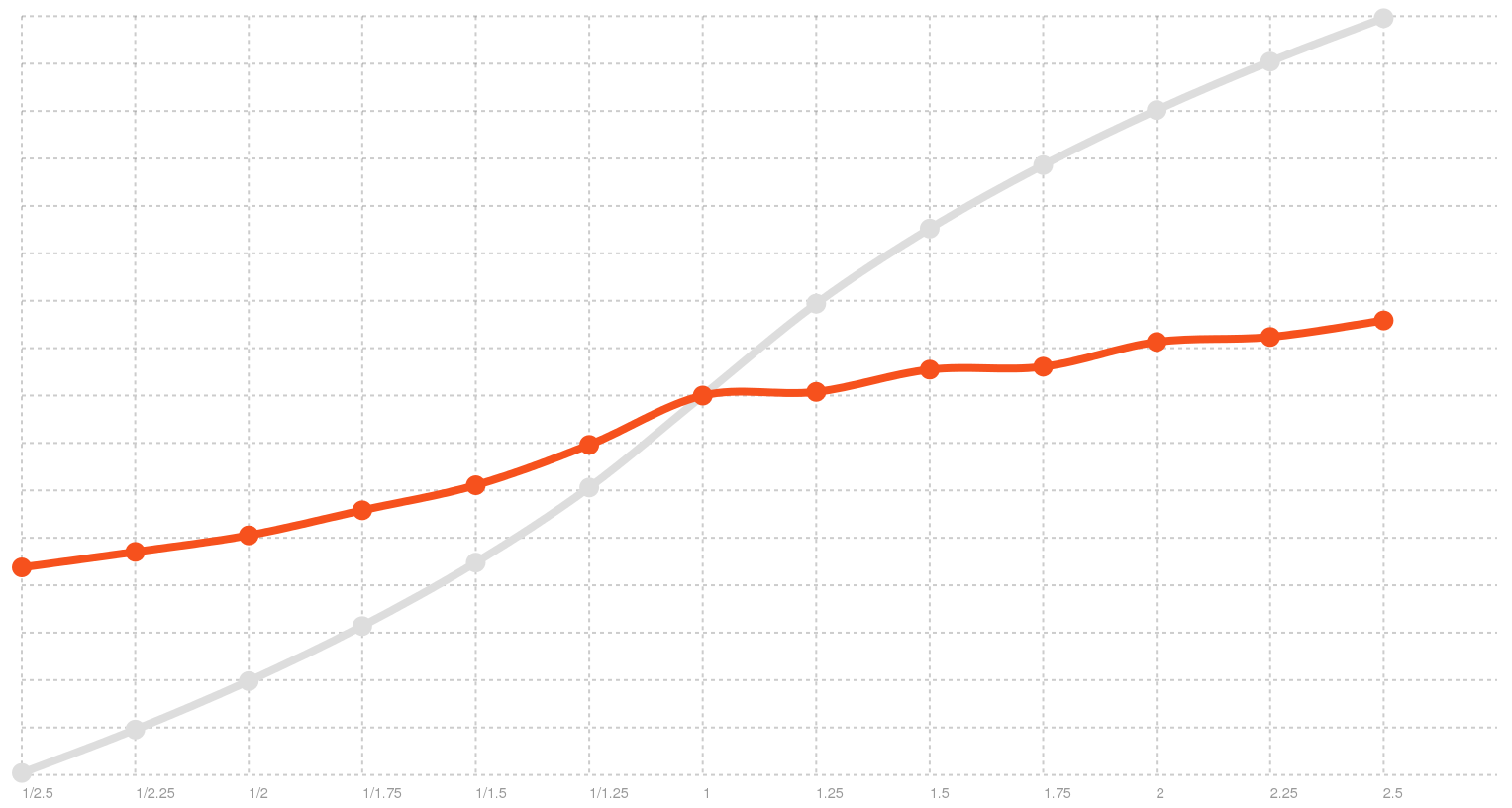 Broken rate distribution on Linux
Broken rate distribution on Linux
Speech Dispatcher has limited documentation. But luckily, it is open source, so we just need to read the code, right? I guess. Theoretically. But in this case, it just made me go down a rabbit hole. Speech Dispatcher supports a few engines, but in reality most distributions make it hard to use anything that isn’t eSpeak. I looked at the eSpeak speechd configuration file, and it had some interesting numbers. The “normal” rate is 170 eSpeak words per minute. The max is 390, and the min is 80. In a proportional sense that would be a min rate of 0.47, and a max of 2.3.
Adjusting the math in our Speech Dispatcher adapter to those theoretical values made things much better, but not perfect. Reading the code of speechd, and its eSpeak output module didn’t reveal anything else. Instead of relying on bad documentation and fallible “source code”, I decided to just go with the numbers I was seeing in the benchmark. Speech Dispatcher rates max out at 2.5x and won’t go below 1/2x. I put those numbers into our conversion formula, and.. it worked well!
|
Voice
|
1/2.5
|
1/2.25
|
1/2
|
1/1.75
|
1/1.5
|
1/1.25
|
1
|
1.25
|
1.5
|
1.75
|
2
|
2.25
|
2.5
|
|
default
|
0.488
|
0.487
|
0.487
|
0.567
|
0.678
|
0.812
|
1.00
|
1.29
|
1.47
|
1.76
|
1.96
|
2.14
|
2.39
|
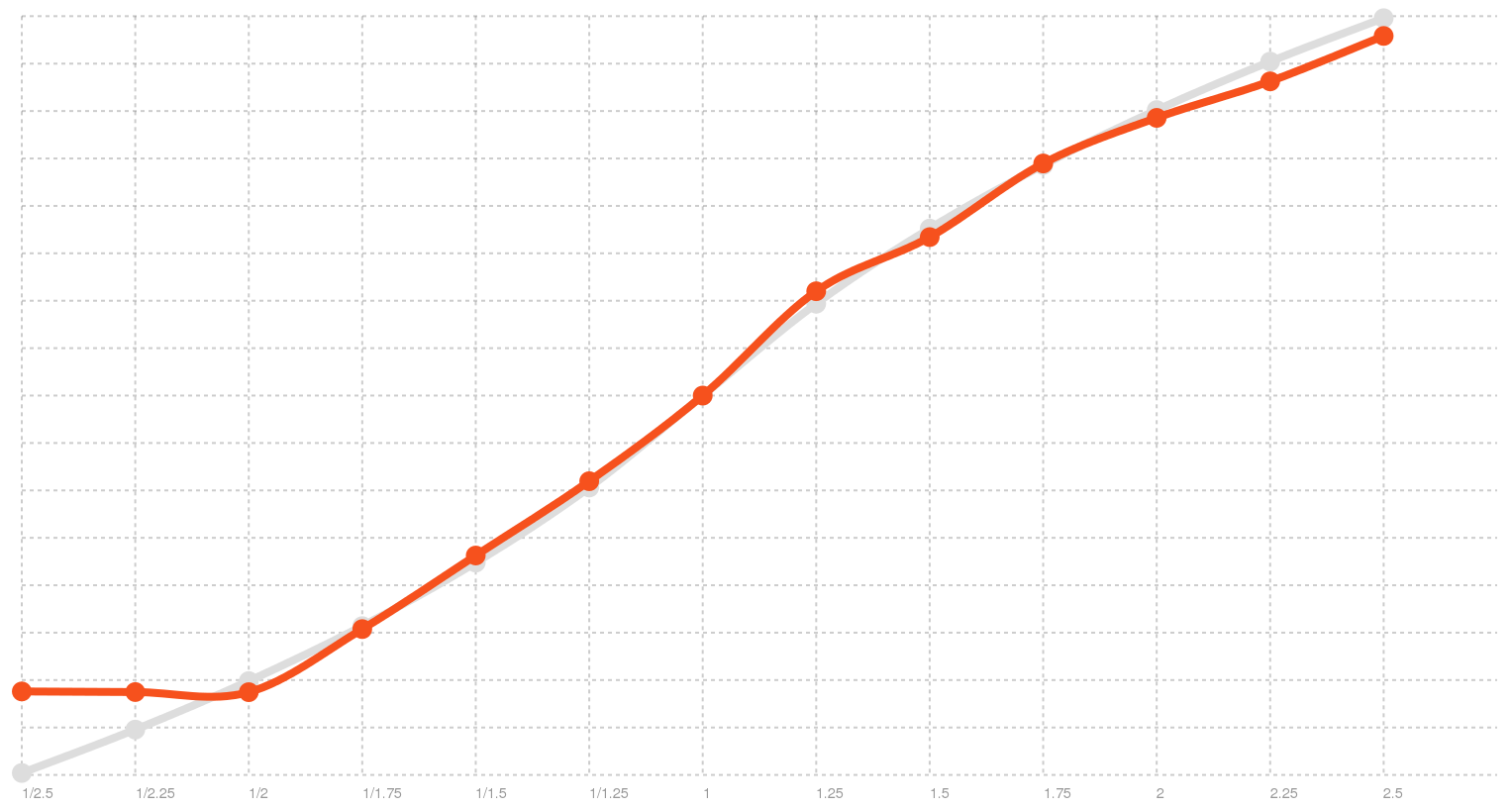 Fixed rate distribution on Linux
Fixed rate distribution on Linux
Conclusion
What’s the lesson to be learned? Not sure. Sometimes the docs are good, other times less so, and sometimes not at all? Benchmarks and real-world results are important?
The one certain thing I know now is that graphs are cool. This is what the rate distribution was before I fixed these issues, check it out:
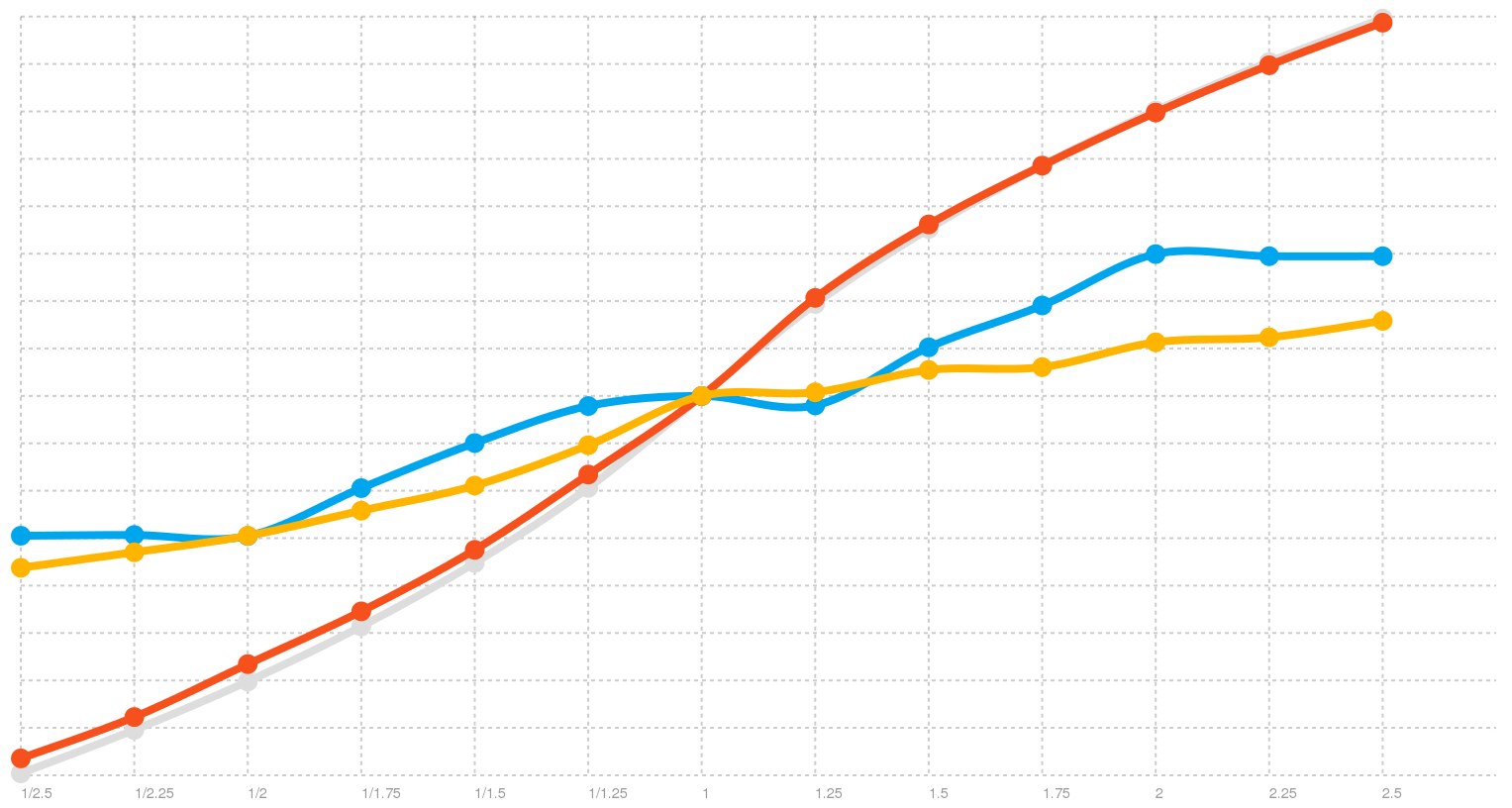 Rate distribution on all three platforms before fix
Rate distribution on all three platforms before fix
And look how clean and nice it is now:
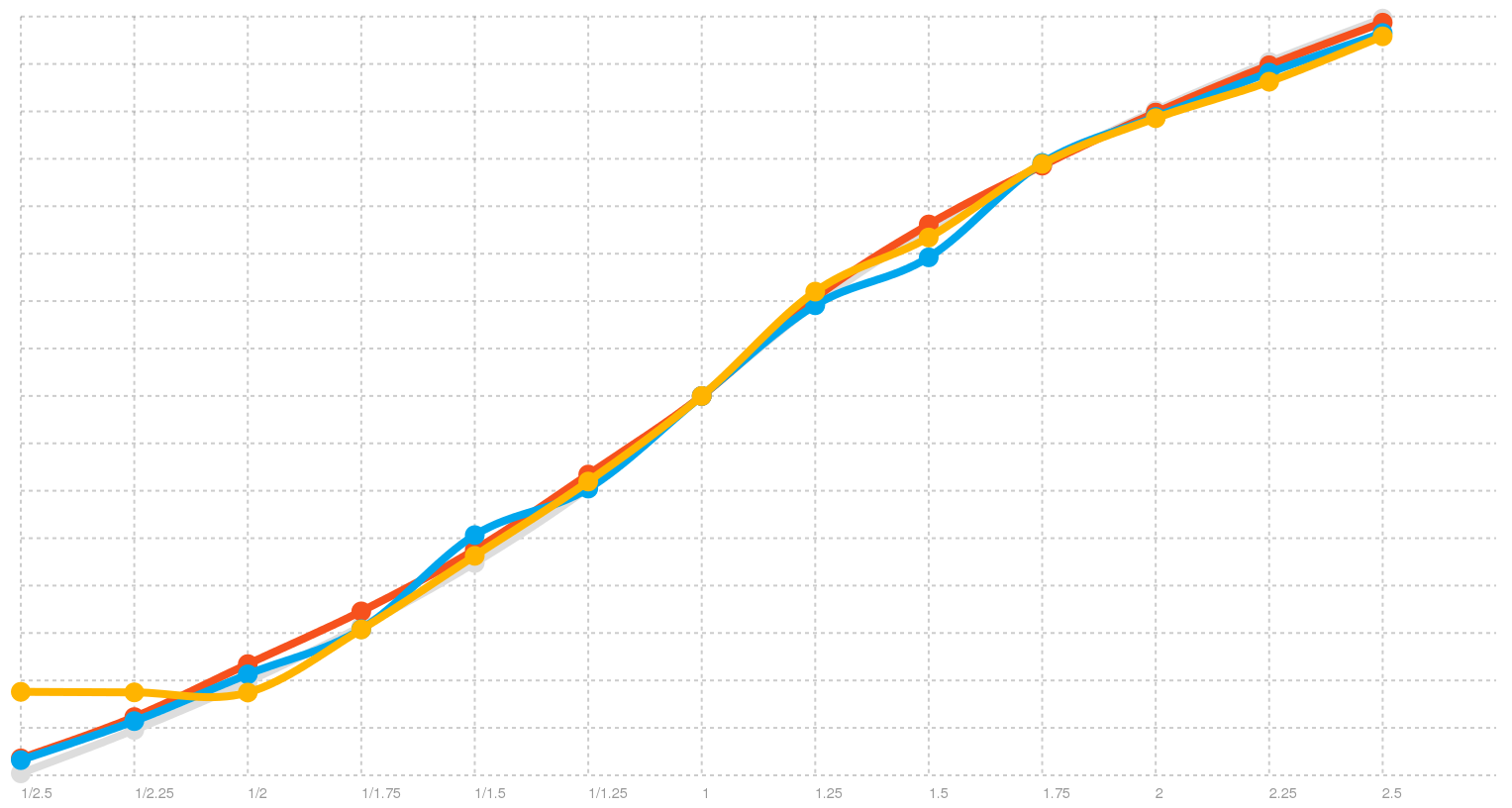 Fixed rate distribution on all three platforms
Fixed rate distribution on all three platforms
While working on the speech synthesis API in Firefox, I have been trying to figure out how to provide the most consistent experience across different desktop platforms. This is tricky, because each platform has its own speech API. Each API has slightly differing feature sets and idiosyncrasies.
A good way to foresee the difficulties others will encounter when writing a cross-platform speech app, is to actually write one. So when we started work on the Narrate feature, I needed to account for the fact that the Linux speech API is not capable of pausing speech mid-utterance. We managed to design the interface in a way that wouldn’t require pausing speech, but still give the user an intuitive way of stopping and starting the narration mid-way through the article.
When we landed Narrate, Ehsan noticed that the speech rate slider in the interface was useless at either extremes. Either silly fast, or glacially slow. Since I was developing this feature on Linux, I didn’t encounter the fast rates OSX users experienced. I first thought this was a bug in our OSX speech synthesis support, but later realized Mac was the exception, and this was an issue with the rate conversion in Linux and Windows.
Speech rate is subjective, in so many ways. What is a “normal” speech rate? I have found many numbers, ranging from 150 to 200 words per minute for US English speakers. Luckily, when it comes to the web API we don’t care what the “normal” rate is, we care about relative rate. But that doesn’t completely solve our conundrum.
The Web Speech API (and SSML) defines the rate as a multiplier of the normal speech rate for a given voice. Meaning, 1 is normal, 2 is twice the speed and 0.5 is half. The speech rate goes through a few conversions:
- Web page provides a rate to the browser
- The browser converts the rate to the platform-specific speech API.
- The speech API converts the rate to the speech engine API.
- In some cases, the voice converts the rate value the engine provides it.
In OSX, life of course is easiest. The rate is defined as words per minute, their docs say “normal” is between 180 to 220. All we need to do is multiply that, and we get a predictable rate. Things get a little hairier on Linux and Windows. In Linux, the Speech Dispatcher API docs says that rate should be an integer between -100 and 100 with 0 being default. In Windows, the situation is not much better: from a cursory glance at the docs for ISpVoice::SetRate, it just specifies that accepted rates are between -10 and 10.
Further digging brought up more information on Linux and Windows that made the rate parameter a bit more understandable:
- In Linux, Speech Dispatcher’s eSpeak output module configuration file shows that the default rate is 160 wpm, the minimum is 80, and the max is 320. That’s pretty conservative, but at least it gives us an idea of what is going on.
- Deeply buried in the Windows docs, I found a mention that the max is 3x normal, and the minimum is a third normal rate.
Now we have something to work with! Did I bore you? I am boring myself..
Next post, a speech rate benchmark tool, pretty graphs, and my attempt at “math”!
Reader View in Firefox makes reading articles, stories and blog posts enjoyable. It removes the noisy background ads and graphics, and gives you a clean single column optimized for your reading pleasure.
As of today’s Nightly build, you will find an extra button in the Reader View toolbar: the Narrate button. Press play in the popup, and you will have the page read out aloud. You are now free to give your eyes a rest, knit, wash dishes, work out, play Candy Crush, whatever.
At Mozilla, we believe the web must remain open and accessible. Accessibility can mean many things. In our accessibility team, we work to make Firefox usable to users with disabilities.
Disability is not a binary, it is more nuanced than that. We define our users broadly, we don’t divide them into users with and without disabilities. There can be many reasons why you would choose to click play on that Narrate popup: eye fatigue, multi-tasking, dyslexia, or Angry Birds.
With features like Narrate, we want to make the web more accessible and convenient for everybody.