- Problem Statement:
- In today’s fast-paced world, while juggling work and personal life, sometimes we need to know what time it is.
- Solution:
- A chronometer you can hang on the wall.
Wake up people. Clocks are the future. Embrace progress.
Hello, my name is Eitan. I am a clock maker.
Over the past year I have spent nights and weekends designing gear trains, circuit boards, soldering and writing software. The result is a clock. Not just any clock, it is a smart clock that could tell you what time it is on demand. It is internet-connected so you can remotely monitor what time it is in your home.
It is powered by three stepper motors, 3 hall effect sensors, and a miniature computer. It also ticks.
 The future of time telling.
The future of time telling.
Why? Because in my hubris I thought it would be an easy weekend project, and then things got out of hand.

Gears
My first gear boxes were pretty elaborate, with different gear ratios for each motor/hand. I probably spent the most time in the design/print cycle trying to come up with a reliable solution that would transfer the torque from 3 separate motors to a single axis. I ended up with something much simpler, a 2:1 gear ratio for all hands.
 An example of an early super elaborate and huge gear box.
An example of an early super elaborate and huge gear box.  My final design.
My final design.
Limit Switches
Another challenge I struggled with was how would the software know where each hand is at any given time? A stepper motor is nice because it has some predictability. Each one of its steps is equal, so if you know that a step size is 6 degrees, it will take 60 steps to complete a rotation. In our case, this isn’t good enough, because:
- The motor is not 100% guaranteed to complete each step. If there is too much resistance on it, it will fail. I struggled to design a perfect gear box that won’t ever make things hard for the motors, but there will be a bad tooth every once in a while that will jam the motor for a step or two.
- The motor I chose for this project is the 28BYJ-48, mainly because it is cheap and you can get a pack of 5 from amazon with drivers for only $12. Its big drawback is that there is no consensus on what the precise step size is. Internally the motor has 32 steps per revolution (11.25 degrees per step). But it has a set of reduction gears embedded in it that make the steps per revolution something like 2037.886. Not a nice number and, more importantly, not good for clocks that risk drifting out of precision.
- When the clock is first turned on, it has no way to know the initial position of each hand.
I decided to solve all this with limit switches. If the clock hands somehow closed a circuit at the top of each rotation, we would at least know where “12 o’clock” is and we will have something to work with. I thought about using buttons, metal contacts and the likes. But I didn’t like the idea of introducing more wear on a delicate mechanical system: how many times will the second hand brush past a contact before screwing it up?
So, I went with latching hall effect sensors. The basic concept is magnets. The sensor will open or close a circuit depending on what pole of a magnet is nearby. I glued tiny magnets at opposite ends of the gears, and by checking the state of the a sensor circuit after every motor step you can tell if we just got to 6 o’clock or 12 o’clock.
 Two magnets on opposite sides of the gear, and the hall effect sensor clamped just above the gear to detect polarity changes.
Two magnets on opposite sides of the gear, and the hall effect sensor clamped just above the gear to detect polarity changes.
Circuits
Electricity is magic to me, I really don’t understand it. I learned just enough to get this project going. I started by reading Adafruit tutorials and breadboarding. After assembling a forest of wires, I finally got a “working” clock. I wanted the final clock to be more elegant than this:

With some graph paper, I sketched out how I can arrange all of the circuits on a perf board and went to work soldering, after inhaling a lot of toxic fumes and leaving some of my skin on the iron I got this:

I was happy with the result, but it could be prettier. Plus, I would never put myself through that again. I wanted to make this process as easy as possible. So I decided to splurge a bit, I redesigned the board using Fritzing:
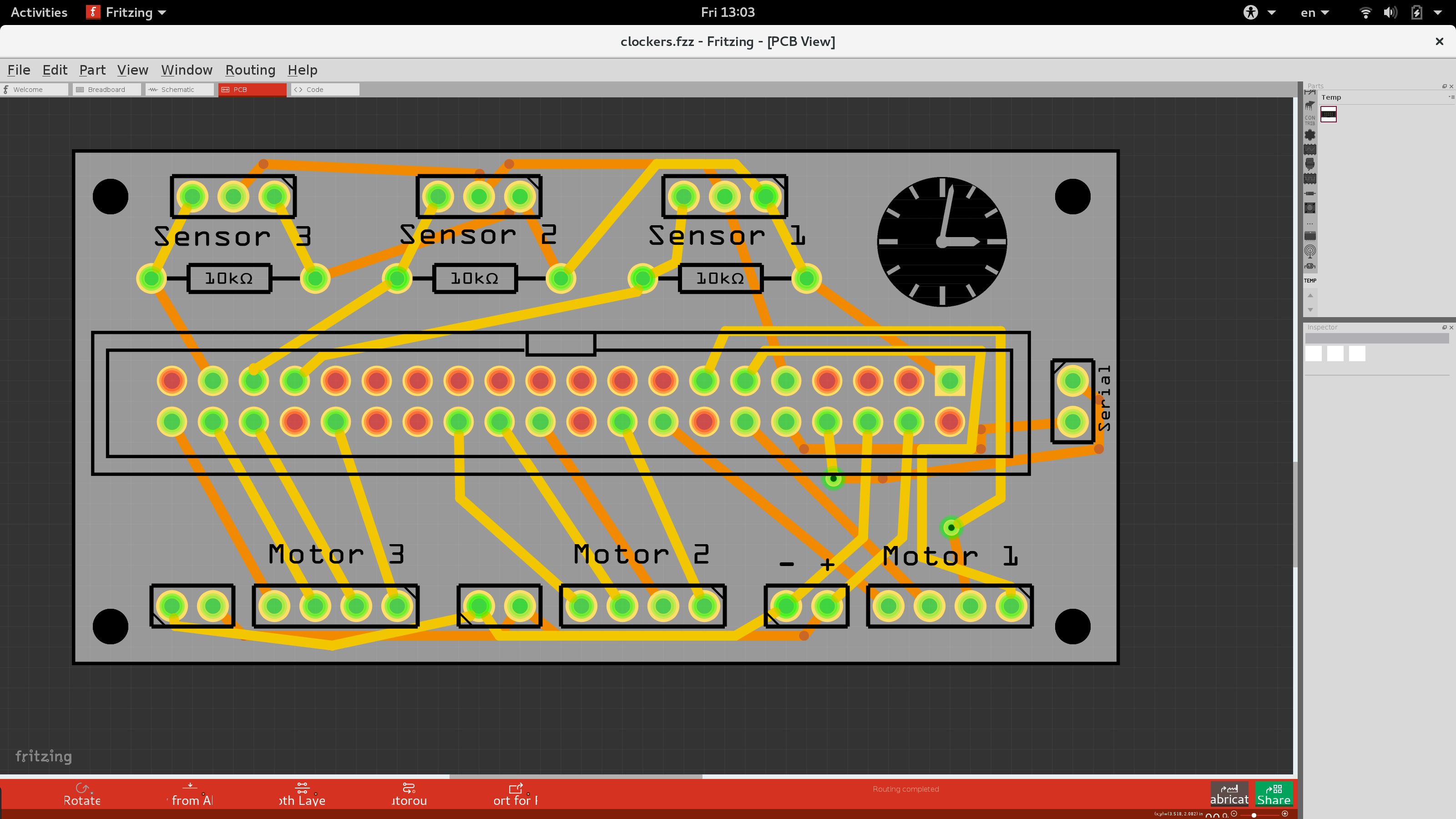
…and ordered PCB prints from their online service. After a month or so I got these in the mail:
 Custom PCBs printed in Berlin!
Custom PCBs printed in Berlin!
Soldering on components was a breeze…
 PCB with jumper headers and resistors.
PCB with jumper headers and resistors.
Software
Software is my comfort zone, you don’t get burnt, electrocuted, or spend a whole day 3D printing just to find out your design is shit. My plan was to compensate for all the hardware imperfection in software. Have it be self-tuning, smart and terrific.
I chose to have NodeJS drive the clock. Mostly because I have recently got comfortable with it, but also because it is easy to give this project a slick web interface.
Doing actual GPIO calls to move the motors didn’t work well in JS. Python wasn’t cutting it either. I needed to move 3 motors simultaneously at intervals below 20 milliseconds. The CPU halts to a stop. So I ended writing a small C program that actually does all the GPIO bits. You start it with an RPM as an argument, and it will do the rest. It doesn’t make sense to spawn a new process on each clock tick, so instead I have the JS code send a signal to the process each second.
With the help of the Network Time Protocol and some fancy high school algebra I was able to make the clock precise to the second. Just choose a timezone, and it will do the rest. It should even switch back and fourth from daylight savings time (haven’t actually tested that, waiting for DST to naturally end).
Mounting
I went to TAP Plastics, my go-to retailer for all things plastic. I bought a 12″ diameter 3/8″ thick acrylic disc. Drilled some holes, and got to mounting this whole caboodle. This project is starting to take shape! With the help of a few colorful wires for extra flourish:
 All the components mounted on the acrylic disc.
All the components mounted on the acrylic disc.
In Conclusion
The slick marketing from Apple and Samsung will have you believe that your life isn’t complete without their latest smart watch. They are wrong.
Your life isn’t complete because you haven’t built your own smart clock. Prime your soldering iron and get to work!
Here in our house we keep our plants on the threshold of death. They are in constant limbo as we remember to water them every few months. It is really quite disgraceful.
 Our sad sad plant.
Our sad sad plant.
One day I looked at our plants and thought we needed to do something. Go and water them? The plant doesn’t just need water. It is suffering from the systemic problem of us never remembering to water it. No. Watering the plant would be too easy, we need a technological solution that will hydrate the plant and not require us to change our comfortable habit of neglect.
I googled “automated house plant watering” and the first link that comes up is an instructable. It promised to be a cheap and easy project. So I went ahead and got all the materials: an aquarium air pump, some tubing and valves. I then followed the instructions and assembled the parts as they describe. The result was underwhelming. I got some gurgling at the plant end of the tube, not a steady or measurable flow. I really don’t understand the physics that makes that system work, but it has a lot to do with water pressure: the deeper your reservoir the more efficient the water gets pumped. As the water gets consumed, the pump gives less output. So to get an optimal plant-watering we would need to make sure the tank is always full. Whats the point of automating it if you have to fill the tank after every watering?? This won’t do. I plan to put this on a timer. I need to know that if I have it on for 1 minute I will always pump a comparable amount of water to the plant.
So I got to thinking, how can an air pump pump water? Specifically, how can it pump water with a constant pressure? I came up with this schematic:
 Air is pumped into a sealed jar with an outlet tube that relieves the jar’s pressure by pushing water out through another tube!
Air is pumped into a sealed jar with an outlet tube that relieves the jar’s pressure by pushing water out through another tube!
I grabbed a mason jar and drilled two 3/16″ holes in the lid. This allowed me to insert the two air tube which are slightly thicker (5mm). They fit snuggly and formed a seal.

Next I attached one of the tubes to the pump, and placed the second one’s end in a glass. Turned on the pump and! Yes! It works! Science! I was getting a steady flow of water. The jar was emptied in a constant rate. This setup will do. I’m so pleased with this!
I splurged and got a slightly more expensive pump with 4 outputs so I can water 4 plants individually.

This setup has a few advantages over other pump setups:
- It is cheap. So far the bill of parts is around $12.50.
- It offers predictable water throughput.
- You can connect any sealable container. Don’t want to refill the water after 32oz of watering? Get a gallon jug.
- If the reservoir runs dry the motor won’t catch fire. That apparently is a thing water pumps.
- Since the water is only going through a simple tube and not an expensive motor, you can pump a nutrient solution. If you want to pamper your plants, we don’t.
I made a stupid pump. Why is that cool? Because with a WiFi plug it becomes smart! It is now a Connected Device™. I plugged it into a Bayit WiFi socket, and set it to turn on for 20 seconds each Monday afternoon. That will feed our plants about a 1/2 a cup a week. If we like the results we may extend it to a full cup!
 The Internet is in control!
The Internet is in control!
A Word on WiFi Sockets
They suck. They take the simplest operation of closing a circuit and abstract it in a shitty smartphone app that only works half the time. Well, at least that has been my impression with this Bayit gadget. For my next project I am going to use a Kankun smart plug. Apparently it runs OpenWRT and is very hackable.
Bill of Materials
|
Air Pump
|
$6.99
|
|
Air tube
|
$3.42
|
|
Mason jar
|
$2.09
|
|
Wifi plug
|
$24.99
|